「StatefulWidgetにロジックを直書きしてたら、コードがカオスになってきた…」
そんな悩みをお持ちではありませんか?
結論からお伝えすると、FlutterでMVVMアーキテクチャを採用すれば、UIとビジネスロジックを明確に分離でき、保守性・テスタビリティが大幅に向上します。特にRiverpodと組み合わせることで、シンプルかつ強力な状態管理が実現できます。
この記事では、他のアーキテクチャから移行したい中級者向けに、MVVMの概念説明から実際のTodoアプリ実装まで、コード付きで詳しく解説します。
この記事でわかること
MVVMアーキテクチャの基本概念とFlutterでの適用方法
MVC/MVPとの違いと、MVVMを選ぶべき理由
Riverpodを使ったMVVMの実装パターン
Todoアプリを題材にした実践的なコード例
MVVM導入時の注意点とベストプラクティス
Flutter MVVMとは?30秒でわかる基礎知識
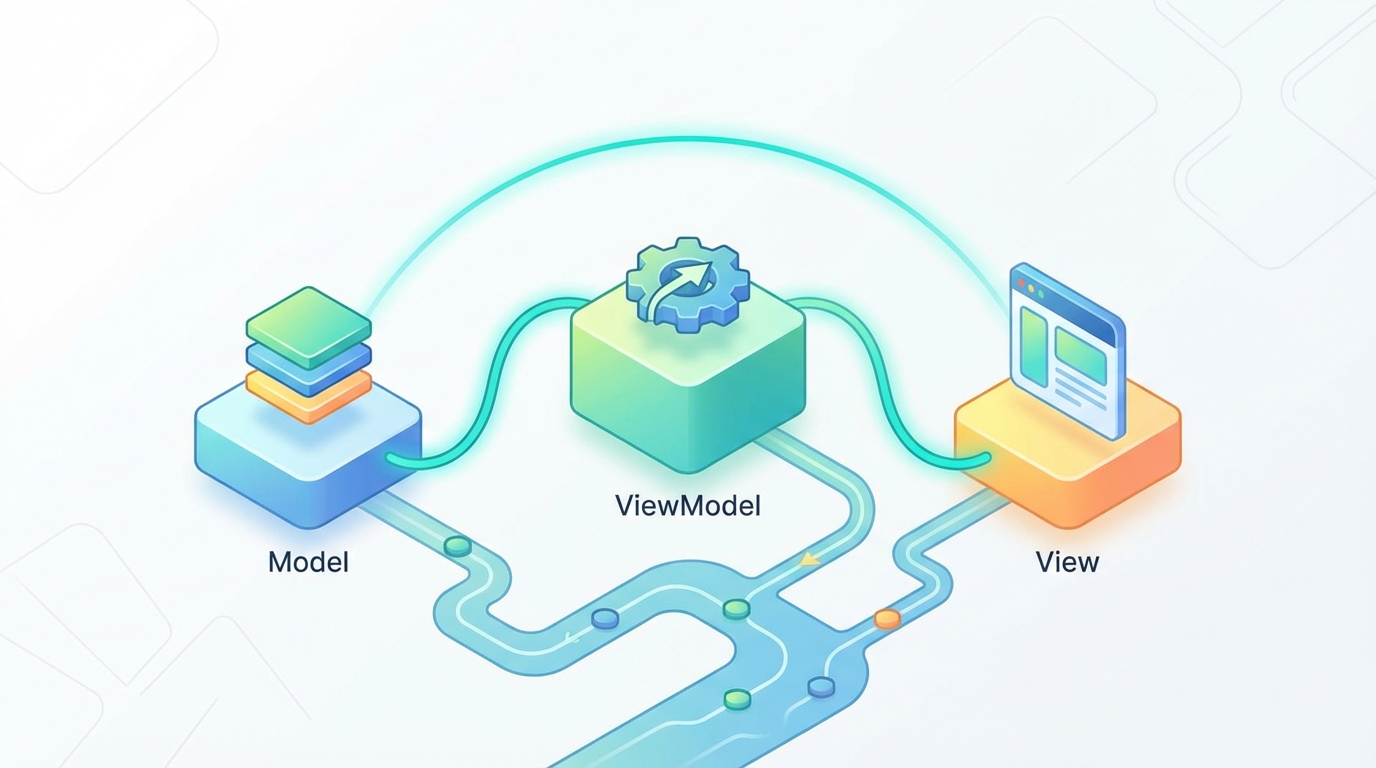
MVVM(Model-View-ViewModel)は、アプリケーションを3つの層に分離するアーキテクチャパターンです。元々はMicrosoftがWPF向けに提唱したものですが、現在ではモバイルアプリ開発でも広く採用されています。
MVVMの3つの構成要素
Model(モデル)
View(ビュー)
ViewModel(ビューモデル)
MVCやMVPとの違い
MVVMと似たパターンにMVC(Model-View-Controller)やMVP(Model-View-Presenter)があります。大きな違いは「ViewとModelの依存関係」です。
MVCでは、ViewがModelの状態を直接参照することがあります。ControllerはユーザーからのInputに対応してModelを操作しますが、ViewとModelが密結合になりやすい傾向があります。
MVVMでは、ViewはViewModelだけを知っていれば良く、Modelの存在を意識しません。ViewModelがModelの状態を監視し、Viewが使いやすい形に加工して提供します。これにより、ViewとModelが完全に分離され、それぞれを独立してテスト・変更できます。
FlutterでMVVMを選ぶメリット
Flutterは宣言的UIフレームワークです。「状態が変わったらUIを再構築する」という考え方は、MVVMのデータバインディングと非常に相性が良いです。
具体的なメリットは以下の通りです。
関心の分離 :UIロジックとビジネスロジックが明確に分かれるテスタビリティ :ViewModelを単体でテストできる再利用性 :ViewModelを別のViewで使い回せるチーム開発 :UI担当とロジック担当で並行作業しやすい
MVVMの各レイヤーの役割と責務
実装に入る前に、各レイヤーの責務をもう少し詳しく整理しておきましょう。
Model層:データとビジネスロジック
Model層には以下が含まれます。
エンティティ/データクラス :Todoアイテム、ユーザー情報などのデータ構造ビジネスロジック :データの検証、計算、変換などのルールRepository :データソース(API、DB、ローカルストレージ)へのアクセスを抽象化
ポイントは、Model層がUIフレームワーク(Flutter)に依存しないことです。純粋なDartコードで書かれ、どこからでも再利用できます。
View層:UIの描画に専念
View層の責務はシンプルです。
ViewModelから受け取ったデータを表示する
ユーザーの操作(タップ、入力など)をViewModelに伝える
View層では、条件分岐やループは許容されますが、ビジネスロジック(「このデータをどう加工するか」「このアクションで何を更新するか」)は書きません。
ViewModel層:状態管理と変換ロジック
ViewModel層が担う責務は以下の通りです。
Viewが必要とする状態を保持・公開する
Modelから取得したデータをView向けに変換する
Viewからのアクションを受け取り、Modelを更新する
非同期処理(API呼び出しなど)の状態管理
Riverpodでは、Notifier(同期)やAsyncNotifier(非同期)がViewModelの役割を果たします。
Repository層:データアクセスの抽象化
厳密にはMVVMの構成要素ではありませんが、実務ではRepository層を追加するのが一般的です。
Repositoryは「データをどこから取得するか」を隠蔽します。ViewModelから見ると、データがAPIから来るのか、ローカルDBから来るのか、キャッシュから来るのかを意識する必要がありません。これにより、データソースの切り替えやテスト時のモック差し替えが容易になります。
RiverpodでMVVMを実装する
FlutterでMVVMを実装する際、状態管理ライブラリの選択が重要です。ここではRiverpodを使用します。
なぜRiverpodか
Riverpodは、Providerパッケージの作者であるRemi Rousselet氏が開発した次世代の状態管理ライブラリです。
Providerと比較した主なメリットは以下の通りです。
コンパイル時安全性 :ProviderNotFoundExceptionのような実行時エラーが発生しないBuildContext不要 :Widgetツリーの外からでもProviderにアクセスできる自動破棄 :使われなくなったProviderは自動的にDisposeされるテストしやすい :Providerのオーバーライドが簡単
BLoCと比較すると、Riverpodはボイラープレートが少なく、学習コストも低めです。MVVMパターンとの相性も良く、NotifierがそのままViewModelとして機能します。
プロジェクト構成(フォルダ構造)
MVVMを採用する際の典型的なフォルダ構成は以下の通りです。
lib/
├── main.dart
├── models/ # Model層
│ └── todo.dart
├── repositories/ # Repository層
│ └── todo_repository.dart
├── view_models/ # ViewModel層
│ └── todo_view_model.dart
├── views/ # View層
│ ├── todo_list_view.dart
│ └── widgets/
│ └── todo_item.dart
└── providers/ # Providerの定義
└── providers.dart
機能ごとにフォルダを分ける(feature-first)アプローチもありますが、小〜中規模のプロジェクトでは、上記のレイヤーごとの構成がシンプルでわかりやすいです。
必要なパッケージ
pubspec.yamlに以下を追加します。
dependencies:
flutter:
sdk: flutter
flutter_riverpod: ^2.5.1
freezed_annotation: ^2.4.1
dev_dependencies:
flutter_test:
sdk: flutter
build_runner: ^2.4.8
freezed: ^2.4.7
freezedはイミュータブルなデータクラスを簡単に作成するためのパッケージです。Model層のデータクラス定義に使用します。
なお、2025年9月にRiverpod 3.0がリリースされ、自動リトライ機能やオフラインサポートなどの新機能が追加されています。本記事のコードはRiverpod 2.x系で動作しますが、3.0への移行も比較的スムーズに行えます。
【実装】TodoアプリでMVVMを体験
それでは、実際にTodoアプリを作りながらMVVMの実装方法を見ていきましょう。
Model層の実装
まず、Todoアイテムのデータクラスを定義します。
// lib/models/todo.dart
import ‘package:freezed_annotation/freezed_annotation.dart’;
part ‘todo.freezed.dart’;
part ‘todo.g.dart’;
@freezed
class Todo with _$Todo {
const factory Todo({
required String id,
required String title,
@Default(false) bool isCompleted,
DateTime? createdAt,
}) = _Todo;
factory Todo.fromJson(Map json) => _$TodoFromJson(json);
}
freezedを使うことで、copyWith、==演算子、hashCode、toStringなどが自動生成されます。以下のコマンドでコード生成を実行します。
flutter pub run build_runner build –delete-conflicting-outputs
Repository層の実装
次に、Todoデータへのアクセスを抽象化するRepositoryを作成します。
// lib/repositories/todo_repository.dart
import ‘../models/todo.dart’;
abstract class TodoRepository {
Future<List> fetchTodos();
Future addTodo(Todo todo);
Future updateTodo(Todo todo);
Future deleteTodo(String id);
}
// インメモリ実装(実際のアプリではAPI呼び出しやDB操作に置き換え)
class InMemoryTodoRepository implements TodoRepository {
final List _todos = [];
@override
Future<List> fetchTodos() async {
// APIコールをシミュレート
await Future.delayed(const Duration(milliseconds: 500));
return List.unmodifiable(_todos);
}
@override
Future addTodo(Todo todo) async {
await Future.delayed(const Duration(milliseconds: 200));
_todos.add(todo);
}
@override
Future updateTodo(Todo todo) async {
await Future.delayed(const Duration(milliseconds: 200));
final index = _todos.indexWhere((t) => t.id == todo.id);
if (index != -1) {
_todos[index] = todo;
}
}
@override
Future deleteTodo(String id) async {
await Future.delayed(const Duration(milliseconds: 200));
_todos.removeWhere((t) => t.id == id);
}
}
抽象クラスを定義しておくことで、テスト時にモックに差し替えたり、将来的にFirestoreやSQLiteに移行したりすることが容易になります。
ViewModel層の実装(Notifier)
ViewModelとして機能するNotifierを実装します。
// lib/view_models/todo_view_model.dart
import ‘package:flutter_riverpod/flutter_riverpod.dart’;
import ‘../models/todo.dart’;
import ‘../repositories/todo_repository.dart’;
// Todoリストの状態を管理するViewModel
class TodoListNotifier extends AsyncNotifier<List> {
late final TodoRepository _repository;
@override
Future<List> build() async {
_repository = ref.read(todoRepositoryProvider);
return _repository.fetchTodos();
}
// Todoを追加
Future addTodo(String title) async {
final newTodo = Todo(
id: DateTime.now().millisecondsSinceEpoch.toString(),
title: title,
createdAt: DateTime.now(),
);
// 楽観的更新:UIを先に更新
state = AsyncData([…state.value ?? [], newTodo]);
try {
await _repository.addTodo(newTodo);
} catch (e) {
// エラー時はリフェッチ
state = await AsyncValue.guard(() => _repository.fetchTodos());
rethrow;
}
}
// Todoの完了状態を切り替え
Future toggleTodo(String id) async {
final todos = state.value ?? [];
final index = todos.indexWhere((t) => t.id == id);
if (index == -1) return;
final todo = todos[index];
final updatedTodo = todo.copyWith(isCompleted: !todo.isCompleted);
// 楽観的更新
final updatedList = […todos];
updatedList[index] = updatedTodo;
state = AsyncData(updatedList);
try {
await _repository.updateTodo(updatedTodo);
} catch (e) {
state = await AsyncValue.guard(() => _repository.fetchTodos());
rethrow;
}
}
// Todoを削除
Future deleteTodo(String id) async {
final todos = state.value ?? [];
// 楽観的更新
state = AsyncData(todos.where((t) => t.id != id).toList());
try {
await _repository.deleteTodo(id);
} catch (e) {
state = await AsyncValue.guard(() => _repository.fetchTodos());
rethrow;
}
}
// 完了済みTodoの数を取得(派生状態)
int get completedCount =>
state.value?.where((t) => t.isCompleted).length ?? 0;
// 未完了Todoの数を取得
int get pendingCount =>
state.value?.where((t) => !t.isCompleted).length ?? 0;
}
ポイントは「楽観的更新」です。APIの応答を待たずにUIを先に更新することで、ユーザー体験が向上します。エラー発生時は、サーバーから最新データを再取得して状態を修正します。
Providerの定義
ProviderをまとめたファイルI作成します。
// lib/providers/providers.dart
import ‘package:flutter_riverpod/flutter_riverpod.dart’;
import ‘../repositories/todo_repository.dart’;
import ‘../view_models/todo_view_model.dart’;
// Repositoryのプロバイダー
final todoRepositoryProvider = Provider((ref) {
return InMemoryTodoRepository();
});
// ViewModelのプロバイダー
final todoListProvider = AsyncNotifierProvider<TodoListNotifier, List>(
TodoListNotifier.new,
);
// 派生状態:完了済みTodoの数
final completedCountProvider = Provider((ref) {
final todosAsync = ref.watch(todoListProvider);
return todosAsync.value?.where((t) => t.isCompleted).length ?? 0;
});
// 派生状態:未完了Todoの数
final pendingCountProvider = Provider((ref) {
final todosAsync = ref.watch(todoListProvider);
return todosAsync.value?.where((t) => !t.isCompleted).length ?? 0;
});
View層の実装
最後に、UIを実装します。
// lib/views/todo_list_view.dart
import ‘package:flutter/material.dart’;
import ‘package:flutter_riverpod/flutter_riverpod.dart’;
import ‘../providers/providers.dart’;
import ‘../models/todo.dart’;
class TodoListView extends ConsumerWidget {
const TodoListView({super.key});
@override
Widget build(BuildContext context, WidgetRef ref) {
final todosAsync = ref.watch(todoListProvider);
final completedCount = ref.watch(completedCountProvider);
final pendingCount = ref.watch(pendingCountProvider);
return Scaffold(
appBar: AppBar(
title: const Text(‘Todo App (MVVM)’),
actions: [
Center(
child: Padding(
padding: const EdgeInsets.only(right: 16),
child: Text(‘完了: $completedCount / 残り: $pendingCount’),
),
),
],
),
body: todosAsync.when(
data: (todos) => todos.isEmpty
? const Center(child: Text(‘Todoがありません’))
: ListView.builder(
itemCount: todos.length,
itemBuilder: (context, index) {
final todo = todos[index];
return TodoItem(todo: todo);
},
),
loading: () => const Center(child: CircularProgressIndicator()),
error: (error, stack) => Center(
child: Column(
mainAxisAlignment: MainAxisAlignment.center,
children: [
Text(‘エラー: $error’),
ElevatedButton(
onPressed: () => ref.invalidate(todoListProvider),
child: const Text(‘再読み込み’),
),
],
),
),
),
floatingActionButton: FloatingActionButton(
onPressed: () => _showAddTodoDialog(context, ref),
child: const Icon(Icons.add),
),
);
}
void _showAddTodoDialog(BuildContext context, WidgetRef ref) {
final controller = TextEditingController();
showDialog(
context: context,
builder: (context) => AlertDialog(
title: const Text(‘新しいTodo’),
content: TextField(
controller: controller,
autofocus: true,
decoration: const InputDecoration(
hintText: ‘Todoのタイトル’,
),
),
actions: [
TextButton(
onPressed: () => Navigator.pop(context),
child: const Text(‘キャンセル’),
),
TextButton(
onPressed: () {
final title = controller.text.trim();
if (title.isNotEmpty) {
ref.read(todoListProvider.notifier).addTodo(title);
Navigator.pop(context);
}
},
child: const Text(‘追加’),
),
],
),
);
}
}
// Todoアイテムのウィジェット
class TodoItem extends ConsumerWidget {
final Todo todo;
const TodoItem({super.key, required this.todo});
@override
Widget build(BuildContext context, WidgetRef ref) {
return Dismissible(
key: Key(todo.id),
direction: DismissDirection.endToStart,
onDismissed: (_) {
ref.read(todoListProvider.notifier).deleteTodo(todo.id);
},
background: Container(
color: Colors.red,
alignment: Alignment.centerRight,
padding: const EdgeInsets.only(right: 16),
child: const Icon(Icons.delete, color: Colors.white),
),
child: ListTile(
leading: Checkbox(
value: todo.isCompleted,
onChanged: (_) {
ref.read(todoListProvider.notifier).toggleTodo(todo.id);
},
),
title: Text(
todo.title,
style: TextStyle(
decoration: todo.isCompleted
? TextDecoration.lineThrough
: TextDecoration.none,
color: todo.isCompleted ? Colors.grey : null,
),
),
),
);
}
}
main.dartの設定
最後に、アプリのエントリーポイントを設定します。
// lib/main.dart
import ‘package:flutter/material.dart’;
import ‘package:flutter_riverpod/flutter_riverpod.dart’;
import ‘views/todo_list_view.dart’;
void main() {
runApp(
const ProviderScope(
child: MyApp(),
),
);
}
class MyApp extends StatelessWidget {
const MyApp({super.key});
@override
Widget build(BuildContext context) {
return MaterialApp(
title: ‘Flutter MVVM Demo’,
theme: ThemeData(
colorScheme: ColorScheme.fromSeed(seedColor: Colors.blue),
useMaterial3: true,
),
home: const TodoListView(),
);
}
}
これで、MVVMアーキテクチャに基づいたTodoアプリが完成です。
MVVMを導入するときの注意点
MVVMは強力なパターンですが、導入時にいくつか注意すべき点があります。
ViewModelが肥大化しやすい問題
すべてのロジックをViewModelに詰め込むと、巨大なクラスになりがちです。対策として以下を意識しましょう。
ビジネスロジックはModel層(またはUseCase層)に分離する
1つのViewModelは1つの画面または機能に対応させる
複数の画面で共有する状態は、別のProviderに切り出す
テスタビリティを意識した設計
MVVMのメリットを最大限活かすには、テストしやすい設計が重要です。
Repositoryは抽象クラス(インターフェース)として定義する
ViewModelはRepositoryをコンストラクタで受け取る(依存性注入)
Providerのオーバーライド機能を活用してモックを差し替える
// テスト例
void main() {
test(‘addTodoでリストに追加される’, () async {
final container = ProviderContainer(
overrides: [
todoRepositoryProvider.overrideWithValue(MockTodoRepository()),
],
);
final notifier = container.read(todoListProvider.notifier);
await notifier.addTodo(‘テストTodo’);
final todos = container.read(todoListProvider).value;
expect(todos?.length, 1);
expect(todos?.first.title, ‘テストTodo’);
});
}
小規模アプリには過剰な場合も
MVVMは中〜大規模アプリで真価を発揮します。数画面程度の小規模アプリでは、オーバーエンジニアリングになる可能性があります。
プロジェクトの規模や将来の拡張性を考慮して、適切なアーキテクチャを選択しましょう。小さく始めて、複雑になってきたらMVVMに移行するアプローチも有効です。
よくある質問(FAQ)
Q. BLoCとの使い分けは?
BLoCとMVVM(Riverpod)は、どちらも状態管理とUIの分離を目的としています。
BLoCはStreamベースで、イベント駆動のアプローチを取ります。複雑な非同期フローや、厳格なアーキテクチャルールを求めるチームに向いています。一方、Riverpodはよりシンプルで柔軟性が高く、学習コストも低めです。
チームの経験や好み、プロジェクトの要件に応じて選択してください。どちらを選んでも、MVVMの考え方(UIとロジックの分離)は適用できます。
Q. Clean Architectureとの関係は?
Clean Architectureは、MVVMよりも広範なアーキテクチャパターンです。Domain層、Data層、Presentation層という3層構造を持ち、依存関係のルール(内側から外側への依存のみ許可)を定めています。
MVVMはPresentationルの設計パターンとして、Clean Architectureの中に組み込むことができます。大規模プロジェクトでは、Clean Architecture + MVVMの組み合わせがよく採用されます。
Q. 既存プロジェクトへの導入方法は?
一度にすべてを書き換える必要はありません。以下のステップで段階的に移行できます。
まずRiverpodを導入し、新規画面からMVVMで実装する
既存画面のリファクタリング時に、少しずつMVVMに移行する
共通のRepositoryやProviderを整備していく
StatefulWidgetのsetStateで管理していた状態を、まずStateNotifierProviderに移すところから始めるのがおすすめです。
まとめ:MVVMで保守性の高いFlutterアプリを
この記事では、FlutterにおけるMVVMアーキテクチャの実装方法を解説しました。
重要ポイント
MVVMは、Model(データ)・View(UI)・ViewModel(状態管理)の3層に分離するパターン
Flutterの宣言的UIとMVVMのデータバインディングは相性が良い
Riverpodを使えば、シンプルかつ強力なMVVM実装が可能
Repository層を追加することで、データアクセスを抽象化できる
楽観的更新でUXを向上させ、エラー時はリフェッチで整合性を保つ
次のステップ
この記事のTodoアプリを実際に動かしてみる
自分のプロジェクトで1画面だけMVVMで実装してみる
テストコードを書いて、テスタビリティの向上を体感する
必要に応じてClean ArchitectureやDDD(ドメイン駆動設計)を学ぶ
MVVMは「銀の弾丸」ではありませんが、UIとビジネスロジックを分離する明確な指針を与えてくれます。まずは小さく始めて、徐々にパターンに慣れていってください。






-10.jpg)

とは?E-E-A-Tの評価を高める7つのルール.jpg)


-9.jpg)






-8.jpg)








-7.jpg)







-5.jpg)






-4.jpg)








-3.jpg)








-2.jpg)




-1.jpg)








.jpg)
